
YataNox
[AWS 스터디모임] AWS Monitoring, Troubleshooting & Audits(1) 본문
개요
모니터링이 중요한 이유
우리는 AWS 컴포넌트를 이용해 코드 인프라를 자동으로 안전하게 구성한다.
애플리케이션을 배포하지만 사용자들은 어떻게 우리가 이것을 구성했는지는 관심이 없고 다만 문제없이 작동한다는 점만 중요할 뿐이다.
어떠한 상황에서도 고객 경험은 저하되면 안된다. 특히 회사에 연락을 하여 불만을 가지는 사용자가 나타난다는 점은 그리 좋은 결과는 아니다.
어떻게 하면 문제를 해결하고 예방할 수 있을까?
내부적으로는 아래와 같은 고민을 끝없이 해야한다.
- 문제가 발생하기 전 막을 수 있는가?
- 만약 발생해도 사용자가 발견하기 전 먼저 발견할 수 있는가?
- 성능과 비용을 모니터링할 수 있는가?
- 정지 패턴과 스케일링 방식에 대한 추이를 살펴볼 수 있는가?
그렇기 때문에 모니터링이 아주 중요하다고 할 수 있다.
AWS의 모니터링 요약
AWS CloudWatch:
Amazon Web Services(AWS) 리소스 및 AWS에서 실행되는 애플리케이션을 실시간으로 모니터링하는 서비스
- 메트릭: 주요 메트릭를 수집하고 추적한다.
- 로그: 로그 파일을 수집, 모니터링, 분석하고 저장한다.
- 이벤트: 특정 이벤트가 AWS에서 발생할 때 알림을 보낸다.
- 알람: 메트릭/이벤트에 실시간으로 반응할 수 있다.
메트릭 : 모니터링 변수 (CPU 사용량, 네트워크 입력 등)
AWS X-Ray:
개발자를 위한 일종의 애플리케이션 분석 및 디버깅 서비스
가장 최근의 서비스
- 애플리케이션 성능과 오류에 트러블 슈팅 수행
- 지연 시간을 살펴보고 오류를 실시간으로 확인할 수 있다.
- 마이크로서비스의 분산 추적을 한다.
AWS CloudTrail:
AWS 계정에 대한 거버넌스, 규정 준수, 운영 및 위험 감사를 활성화하는 데 도움이 되는 AWS 서비스
- API 호출이 이루어지는 내부 모니터링을 수행한다.
- 사용자에 의한 AWS 리소스의 변경 사항에 대한 감사를 진행한다.
CloudWatch 지표
CloudWatch는 모든 AWS 서비스에 대해 지표를 제공한다.
- 메트릭은 네임스페이스에 속한다.
- Dimension은 메트릭의 속성이다.(인스턴스 id, 환경 등)
- 메트릭 당 최대 30개의 Dimension을 가지고 있다.
- 메트릭은 타임스탬프를 가지고 있다.
- 메트릭에 대한 CloudWatch 대시보드를 생성할 수 있다.
출처 : https://dev.classmethod.jp/articles/lim-cloudwatch-custom-metrics/
용어
Namespace, Dimension, Metric, Statistics
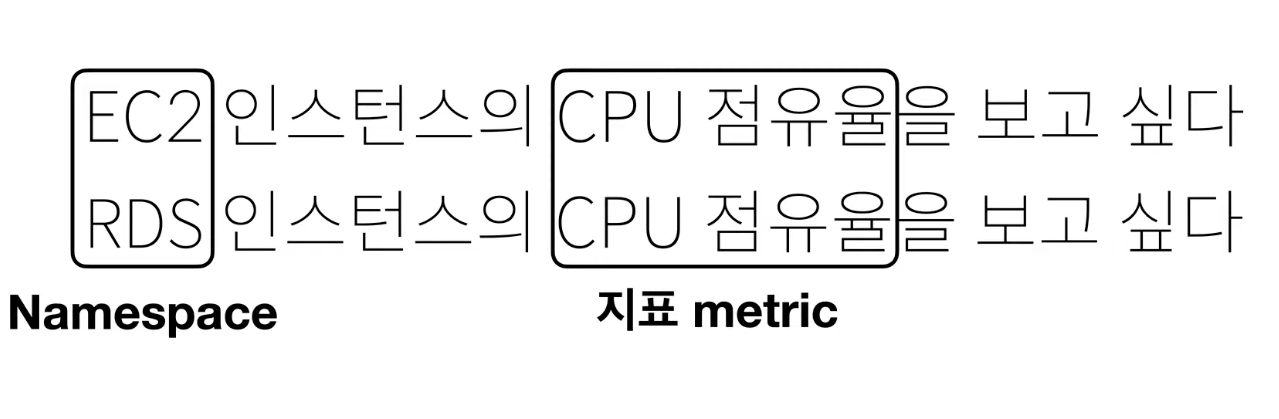
만약, "EC2 인스턴스의 CPU 점유율을 보고 싶다."
"RDS 인스턴스의 CPU 점유율을 보고 싶다." 라고 하면.
EC2, RDS 는 논리적으로 구분하기 위한 Namespace 가 되고
CPU 점유율은 지표값이 됩니다.
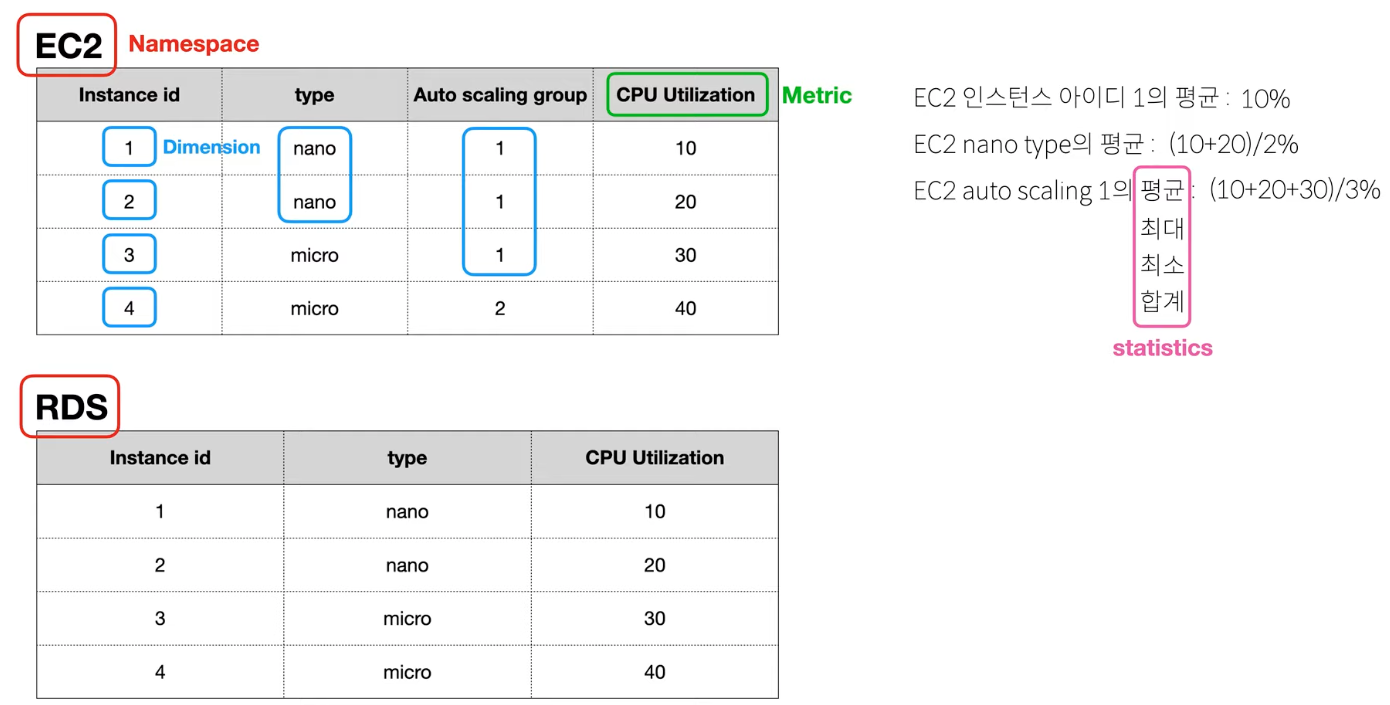
위 표와 같이 AWS 리소스를 가지고 있다고 하면
EC2, RDS 는 Namespace 라고 합니다.
인스턴스 개별로 보거나
인스턴스 유형(type) 으로 묶어서 보거나
같은 오토스케일링 그룹으로 묶어서 보는 것을 Dimension 이라고 합니다.
CPU 자원 사용률은 Metric 값이 됩니다.
자원 사용률에 대한 평균, 최대, 최소 등의 값은 statistics 값이 됩니다.
EC2 상세 모니터링
EC2 인스턴스는 매 5분마다 메트릭을 제공하는데 만약 비용을 좀 들이더라도 상세 모니터링을 사용하면 매 1분마다 메트릭을 제공받을 수 있다.
이 상세 모니터링을 통해 ASG를 더욱 빠르게 처리할 수 있다.
다만 EC2 메모리 사용량은 기본적으로 제공되지 않는다. 내부의 커스텀 메트릭으로 해야한다.
Cloud Custom Metrics
- 커스텀 메트릭을 정의하고 CloudWatch에 전송할 수 있다.
- 메모리 사용량, 디스크 공간, 로그인 유저 수 등
- 사용을 위해 PutMetricData API 호출한다.
- 세그먼트 지표에 배열이나 특성을 추가할 수도 있다.
- 인스턴스.id, 환경.이름 등 여러가지를 추가할 수 있다.
- StorageResolution API를 이용하여 메트릭 해상도의 두 가지 값을 지정할 수 있다.
- 표준 사용자 지정 해상도 : 1분에 한 번 푸쉬
- 고해상도 : 1/5/10/30초 선택 가능. 단 비용이 많이 든다.
- 지표를 2주 전으로 푸시하든 2시간 앞으로 푸시하든 CloudWatch 오류가 발생하지 않는다. 무슨 의미일까?
타임스탬프와 메트릭 데이터
CloudWatch로 메트릭 데이터를 전송할 때, 각 데이터 포인트에는 해당 데이터가 언제 발생했는지를 나타내는 타임스탬프가 포함되어야 한다.. 이 타임스탬프는 메트릭 데이터가 언제의 것인지를 CloudWatch에 알려줍니다.
타임스탬프의 유연성
이제 중요한 부분인데, CloudWatch는 메트릭 데이터의 타임스탬프가 현재 시간과 다소 차이가 나더라도 그 데이터를 받아들입니다. 즉, 사용자는 과거 시점의 데이터를 지금 전송할 수도 있고, 심지어 미래의 시점으로 설정된 데이터를 전송할 수도 있습니다. 이 말은 다음과 같은 시나리오에서 유용할 수 있음을 의미
- 과거 데이터 보정: 만약 어떤 이유로 데이터 수집에 실패하거나 누락된 데이터가 있을 경우, 해당 데이터를 나중에 CloudWatch로 보낼 수 있습니다. 이때 과거의 정확한 시점을 타임스탬프로 설정하여 데이터의 정확성을 유지할 수 있습니다.
- 시간대 처리: 서로 다른 시간대에서 발생한 이벤트를 중앙 집중식으로 모니터링해야 하는 경우, 각 이벤트의 로컬 타임스탬프를 기준으로 데이터를 전송할 수 있습니다.
- 미래 예측 값 기록: 예측 모델이나 시뮬레이션 결과를 미래의 타임스탬프와 함께 CloudWatch로 전송하여 기록할 수도 있습니다.
- 중요한 점은 메트릭을 푸시 하는 시점이 과거든 미래든 상관없다는 점이다. (아주 중요한 시험 포인트)
- 따라서 AWS 실제 시간과 동기화하려면 인스턴스 시간을 잘 확인하여야 한다.
CloudWatch Logs
AWS에서 제공하는 로그 서비스로 애플리케이션의 로그를 저장하기 위한 최고의 서비스이다.
- 사용을 위해서는 가장 먼저 Log Groups을 지정해야한다.
- Log Groups 에는 여러개의 Log stream이 존재한다.
- 애플리케이션 내의 로그 인스턴스나 특정 로그 파일, 특정 컨테이너를 나타낸다.
로그의 대한 삭제 정책도 정의할 수 있다.
영원히 삭제되지 않게 하거나 1일 ~ 10년의 범위를 지정할 수도 있다.
로그를 다른 목적지로 전송하는 것도 가능하다.
- Amazon S3
- Kinesis Data Streams
- AWS Lamda
- etc....
Log는 기본적으로 모두 암호화된다. 원한다면 KMS 기반 암호화를 사용해서 암호화할 수 있다.
KMS( Key Management Service) :
데이터를 암호화 할때 사용되는 암호화 Key 를 안전하게 관리하는데 목적을 둔 서비스
- 로그는 어떤 형태로 CloudWatch Log로 들어갈까?
- SDK나 CloudWatch Log Agent를 사용해서 로그를 보낼 수 있다.(Amazon EC2 인스턴스에서 CloudWatch Logs로 로그 데이터를 자동 전송할 수 있게 해준다.)
- 엘라스틱 빈스톡은 애플리케이션에서 CloudWatch로 직접 로그를 수집한다.
- ECS는 컨테이너에서 로그를 전송한다.
- 람다는 함수 자체에서 로그를 전송한다.
- VPC Flow Logs를 이용해서 VPC의 특화된 로그를 전송할 수 있다.
- API 게이트웨이의 경우는 게이트웨이의 모든 로그를 전송한다.
- CloudTrail 는 필터를 기반으로 로그 전송한다.
- Route53 : 해당 서비스에 수행된 모든 dns 쿼리를 로그로 기록.
CloudWatch Logs Metric Filter
CloudWatch Logs는 필터 표현식으로 로그를 볼 수 있다.
- 로그에서 특정 ip를 찾거나 단어 오류 발생 수를 세는 등의 작업이 가능하다.
- 이러한 메트릭을 만들수 있기에 메트릭 필터라고 부른다.
- 메트릭 필터로 알람을 발생시킬 수 있다.
- 다만 필터는 데이터를 소급하여 필터링하지는 않는다.
- 필터가 생성된 후에 발생하는 이벤트에 대해서만 데이터 포인트를 게시한다.
- 필터의 차원을 3개까지 지정할 수 있다.

CloudWatch Logs Insights
CloudWatch Log에서 로그를 쿼리하기 위한 시스템
- 쿼리에 적용 시간 프레임을 명시하면 자동으로 시각화된 로그를 얻을 수 있다. (결과로 추출 역시 가능하다)
- 샘플 쿼리들도 콘솔에 제공되어 있어서 특정 작업을 미리 제공된 쿼리로 이용할 수 있다.
- 조건으로 필터링을 할 수도있고, 통계를 계산하거나 이벤트를 정렬 혹은 이벤트 수를 제한 할수도 있다.
- 여러 로그 그룹에 동시 쿼리할 수 도 있다.
- 앞서 한 번 설명했듯 여러 목적지로 송신 가능하다.
https://docs.aws.amazon.com/ko_kr/AmazonCloudWatch/latest/logs/CWL_QuerySyntax.html
CloudWatch 로그 인사이트 쿼리 구문 - 아마존 CloudWatch 로그
이 페이지에 작업이 필요하다는 점을 알려 주셔서 감사합니다. 실망시켜 드려 죄송합니다. 잠깐 시간을 내어 설명서를 향상시킬 수 있는 방법에 대해 말씀해 주십시오.
docs.aws.amazon.com
CloudWatch Logs - S3
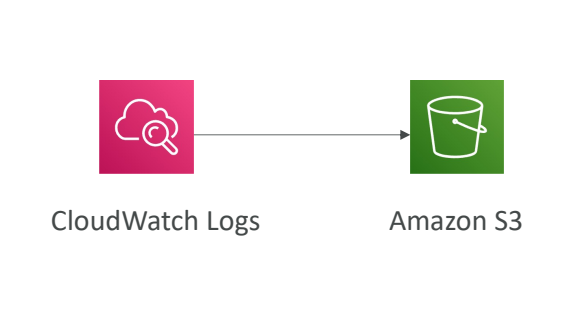
- 배치로 모든 로그를 S3로 내보낼 수 있다.
- 최대 12시간이 걸릴 수 있다.
- CreateExportTask API를 사용하여 실행한다.
- 기본적으로 배치 시스템이기 때문에 실시간 시스템은 아니다. 실시간을 이용하고 싶다면 Log 구독 시스템을 이용해야한다.(구독 필터를 통해서 어떤 유형의 로그 이벤트를 어떤 목적지로 보낼 지 결정한다.)
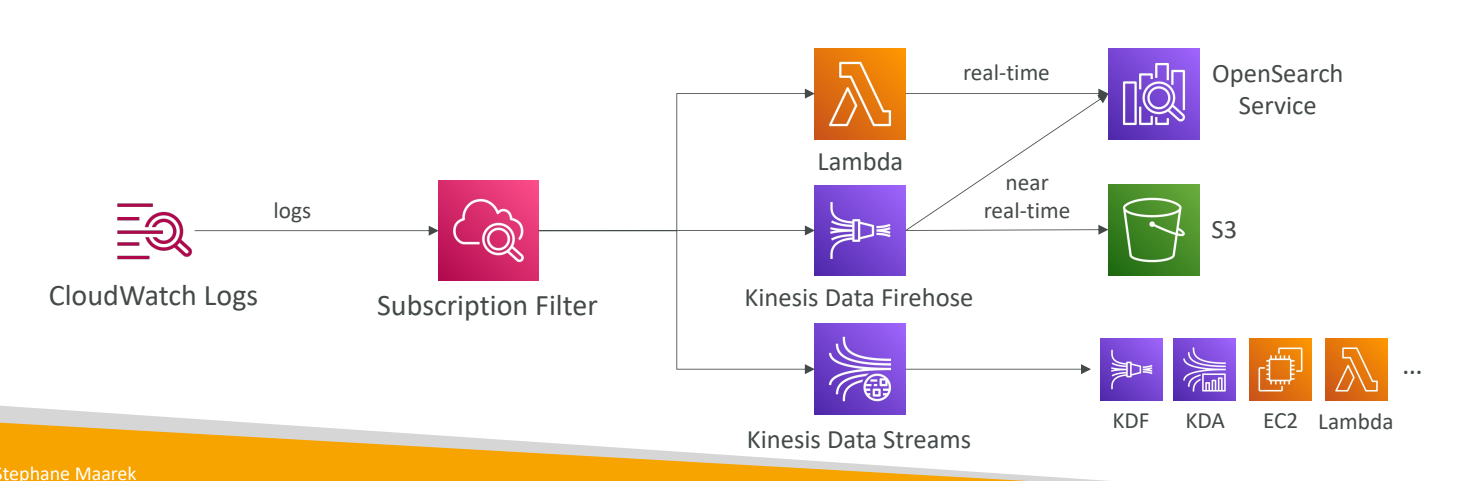
Data Streams, Data Firehose, Lambda 등으로 보낼 수 있다.
구독 필터는 Kinesis Data Streams로 보낼 수 있으며 Kinesis Data Firehose나 Kinesis Data Analytics
EC2 혹은 Lambda와 함께 사용하고 싶다하면 설정을 통해 가능하다.
그리고 Kinesis Data Firehose로 직접 보낼 수도 있으며
거의 실시간으로 Amazon S3에 전송할 수 있다.
OpenSearch 서비스에도 보낼 수 있다.
Lambda로 보내서 직접 Lambda 함수를 작성할 수도 있다.
관리형 Lambda 함수를 사용해서
실시간으로 OpenSearch 서비스에 데이터를 보낼 수 있다.
구독 필터 기능에 의해 서로 다른 계정이나, Region에서 로그를 가져와 통합하는 것도 가능하다.
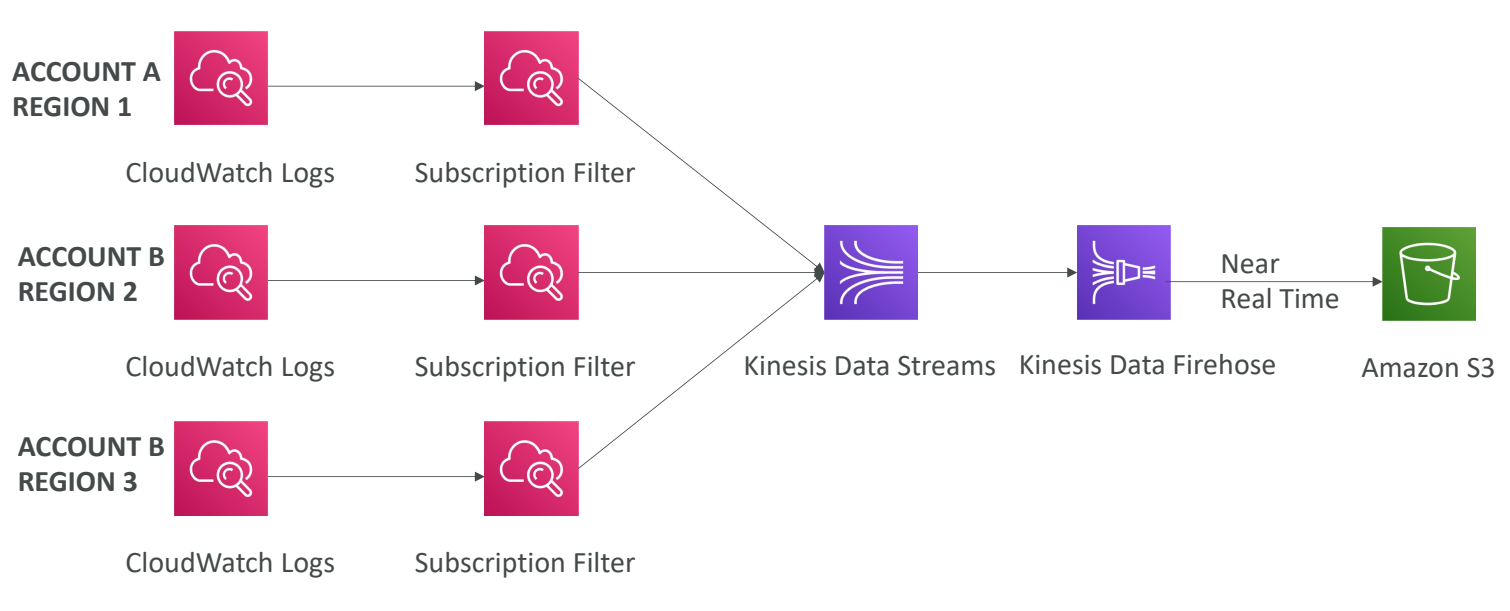
계정 간 구독 : 로그 이벤트나 리소르를 다른 AWS 계정에 보낼 수 있다.
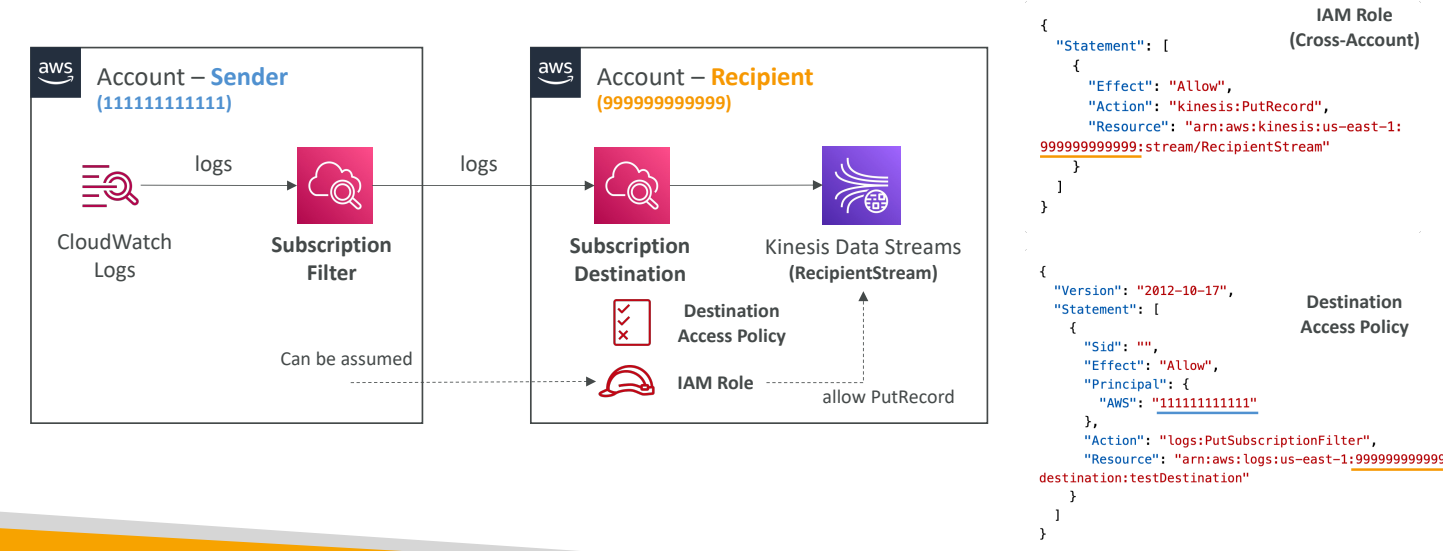
발신자 계정과 수신자 계정이 있다고 할 때,
CloudWatch 로그 구독 필터를 생성한다.
필터에 의해 타 계정의 구독 목적지로 전송된다.
수신자 계정에서 Kinesis Data Streams로 내보내고 송신 계정이 로그를 목적지로 보내는 것을 허용하기 위해 액세스 정책을 가져온다.
이후 수신자 계정에서 Kinesis Data Streams에 데이터를 보낼 수 있는 권한 IAM 역할을 생성한다.
이 모든 것이 준비되면 어떤 계정의 CloudWatch 로그 데이터를 다른 계정의 어떤 목적지로 보내는 데 성공한다.
CloudWatch Log Agent, CloudWatch Agent
기본적으로 제공되는 Infra metric 외 추가적인 system-level metric을 수집할 수 있도록 도와주는 도구이다. 또한, 로그를 수집하는데 이용할 수도 있다. 초단위 로그를 이용하기 위해서도 사용한다.)
CloudWatch Logs for EC2
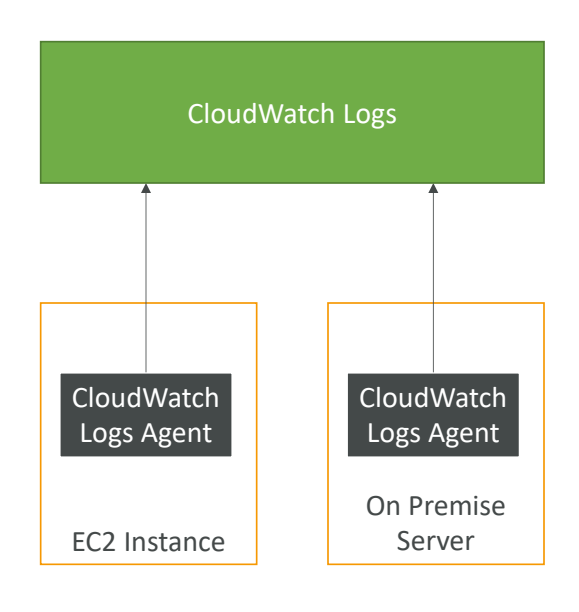
기본적으로 로그를 EC2 인스턴스에서 CloudWatch로 전송할 수는 없다.
이를 위해서 로그 파일을 푸시하는 작은 프로그램인 Agent를 생성해야한다.
EC2 인스턴스에서 CloudWatch Log Agent를 실행하여 로그를 전송해준다.
- 이때 EC2 인스턴스에 IAM 역할이 존재해야한다.
CloudWatch Log Agent는 온프레미스 서버에도 설치가 가능하다.
가상 서버를 온프레미스에 두고 작은 Linux 프로그램같이 동일한 에이전트를 설치하면 로그가 표시된다.
CloudWatch에는 두 가지 에이전트가 있다.
- CloudWatch Log Agent
- CloudWatch Unified Agent
모두 온프레미스 서버의 가상 서버 EC2 인스턴스용.
Logs Agent는 이전 버전으로써 CloudWatch에 로그를 전송하기만 한다.
반면 새로운 버전으로 Unfied Agent는 추가 시스템 수준의 지표를 수집하고 송신한다.
SSM Parameter Store를 사용하기 때문에 에이전트 구성도 쉽다.
에이전트 일체를 중앙집중식으로 구성할 수 있다.
CloudWatch Unified Agent – 메트릭
• Linux 서버/EC2 인스턴스에서 직접 수집
• CPU(액티브, 게스트, 유휴상태, 시스템, 사용자 등)
• Disk 메트릭(사용 가능 여부 , 총계), Disk IO(쓰기, 읽기, 바이트, IOPS)
• RAM(사용 가능 여부 , 비활성, 사용량, 캐시 등)
• Netstat(TCP 및 UDP 연결 수, 넷 패킷, 바이트)
• 프로세스(총, 데드, 블롭, 아이들, 실행, 슬립)
• 스왑 공간(사용 가능, 사용 가능, 사용 가능 %)
• 알림: EC2에 대한 기본 제공 메트릭 – 디스크, CPU, 네트워크(높은 수준)
CloudWacth Alarms
지표에 대한 알림을 트리거할 때 이용하는 서비스.
직접 샘플링하거나, %, 최솟값, 최댓값 등의 옵션을 이용해 복잡한 경보를 정의할 수 있다.
알람에는 3가지 상태가 있는데 아래와 같다
- OK : 경보가 트리거 되지 않은 상태
- INSUFFICIENT_DATA : 데이터가 부족해 경보 상태를 결정할 수 없는 상태
- ALARM : 임계값을 초과해 알람 전송이 예정된 상태
Period 옵션은 지표를 평가하는 시간을 나타낸다.
1초 부터 다양하게 지표 시간을 설정할 수 있다.
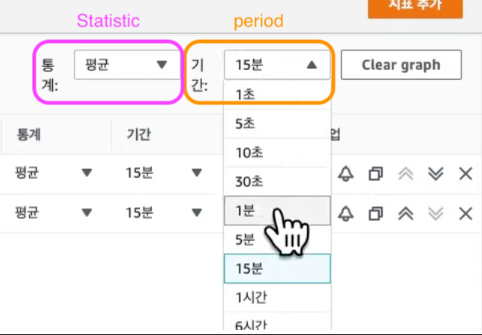
Alarm Target
알람의 대상은 크게 3가지이다.
- EC2 인스턴스에 중지, 종료, 재부팅, 복구 트리거
- 오토 스케일링 동작을 트리거
- 아마존 SNS 서비스에 알림을 전송

람사 함수를 이용해 임계값을 초과할 때마다 원하는 동작을 수행하도록 할 수 있다.
복합 Alarm
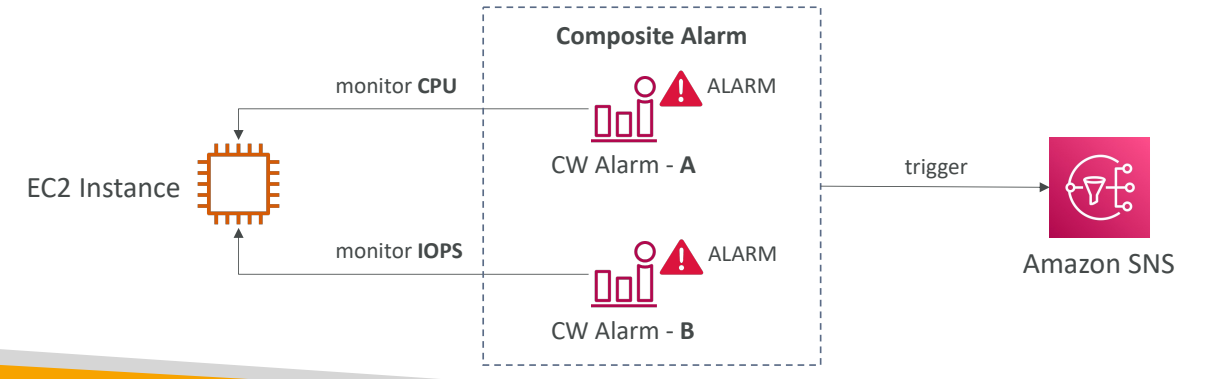
CloudWatch Alarm은 기본적으로 단일 지표를 사용해서 나타낸다.
여기서 여러 지표를 활용해서 상태를 모니터링하고 싶다면 복합 알람을 이용해야한다.
복합 알람은 다른 여러 알람의 상태를 모니터링하고 있는데, 각 알람은 다른 지표를 이용할 수 있기 때문에 서로 다른 여러 알람을 통합하는 작업인 셈이다.
AND나 OR 조건으로 검사할 조건을 설정할 수 있으며 잘만 생성한다면 알람의 노이즈를 줄이는 역할을 할 수 있다.
(Ex : A와 B가 모두 높을 때는 울리지 않고 A만 높을 때 울리게 하는 등)
EC2 Instance Recovery

EC2의 VM 점검이나 하드웨어 점검시에 Alarm을 정의할 수 있다.
EC2 인스턴스를 모니터링 시 알람이 트리거 되면 복구를 실행해 EC2 인스턴스를 다른 호스트로 옮기는 등의 작업을 할 수 있다.
복구된 인스턴스는 비공개 IP, 공개 IP, 탄력적 IP, 메타데이터, 배치 그룹 모두
원본 인스턴스와 동일하며 SNS 주제에 경보를 전송해 EC2 인스턴스가 복구 중이라고 알릴 수 있다.
CloudWatch 경보에 대해 알아 두면 좋은 점들입니다
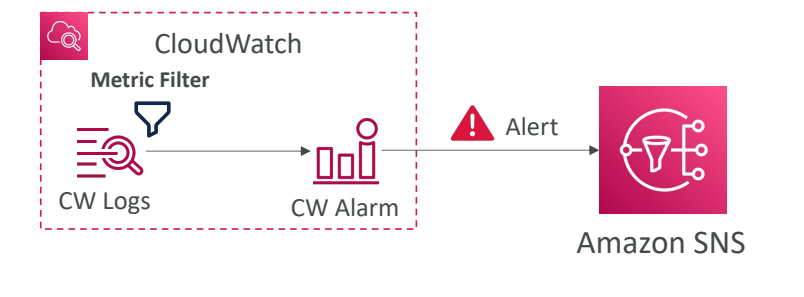
경보 알림을 테스트하고 싶으면 set-alarm-state라는 CLI 요청을 실행하면 된다.
특정 임곗값을 초과하지 않은 상황이지만 일부러 경보를 트리거해서 경보 트리거 시 여러분의 인프라에 올바른 작업이 수행되는지 확인할 때 유용하다.
CloudWatch Synthetics Canary
Canary : 일정에 따라 실행되어 엔드포인트와 API를 모니터링하는 구성 가능한 스크립트
CloudWatch Synthetics는 사용자가 보유한 구성 가능 스크립트를 이용해 Wacth에서 실행하여 API, URL, 웹사이트 등을 모니터링할 수 있게 해주는 서비스이다.
사용자가 스크립트를 정의하면 프로그램에서 똑같이 재현한다.
예를 들어 고객이 상품 페이지로 들어가 상품을 클릭해 장바구니에 담고
결제창에서 신용카드 정보를 입력한 뒤 제대로 결제되는지 확인한다고 할 때
CloudWatch Synthetics Canary로 이 전 과정을 재현해 테스트할 수 있는 것.
만약 스크립트가 실패한다면 이를 통해 고객보다 먼저 문제를 발견할 수 있다.
이뿐만 아니라 가용성과 지연 시간도 점검할 수 있으며 UI 스크린샷도 저장할 수 있다
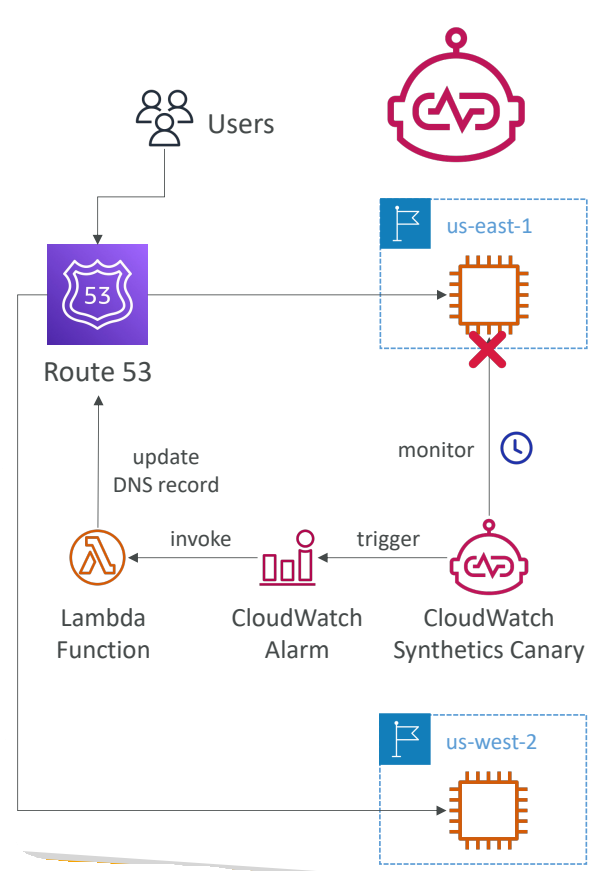
예를 들어
us-east-1에 배포된 애플리케이션이 있는데, CloudWatch Synthetics Canary를 사용해
애플리케이션을 모니터링한다고 하자.
실패할 경우 CloudWatch 경보가 트리거되고 람다 함수가 호출되면서
Route 53의 DNS 레코드를 us-west-2에 있는 다른 인스턴스로 업데이트한다.
그 결과 우리는 애플리케이션이 잘 작동하는 버전으로 리디렉션된다.
스크립트는 Node.js나 Python으로 작성된다. 또한 Canary안에서 구글 크롬 브라우저에 접근 가능하여 작업을 할 수도 있다.
스크립트는 일회성으로 사용하거나 정기적으로 실행할 수 있다.
CloudWatch Synthetics Canary Blueprints
AWS CloudWatch Synthetics를 사용하여 간편하게 시작할 수 있는 사전 정의된 템플릿
웹사이트나 API 같은 애플리케이션의 엔드포인트를 주기적으로 모니터링하는데 도움을 준다.
- 하트비트 모니터 : URL 로드, 스크린샷 HTTP 아카이브 파일을 저장
- API canary : REST API의 기본적인 읽기 쓰기 함수를 제공
- 잘못된 링크 검사기 : 테스트 중인 URL 내부의 모든 링크를 검사
- 시각적 모니터링 : Canary 실행 중 찍은 스크린샷을 이전에 찍은 것과 비교
- canary 레코더 : CloudWatch Synthetics Recorder와 함께 쓰여 웹사이트에서의 동작을 기록하고 그에 대한 스크립트를 자동으로 생성
- GUI 워크플로우 : 웹페이지에서 수행한 동작이 잘 동작하는지 검증.
Amazon EventBridge
이전에 CloudWatch Events 였던 서비스로 다양한 소스의 데이터와 애플리케이션을 연결하는 데 사용할 수 있는 서버리스 이벤트 버스 서비스이다.
- 클라우드에 작업을 스케줄링할 수 있다.
-
한 시간마다 Lambda 함수를 트리거한다고 하고 그 Lambda 함수는 스크립트를 실행하는 거라고 한다면 한 시간마다 Amazon EventBridge 이름으로 이벤트가 발생한다.
-

- 이벤트 패턴에 맞춰서 스크립트를 실행할 수 도 있다.
- 무언가를 하는 서비스에 맞춰서 실행하는 것.
-
예를 들어 IAM 루트 유저가 콘솔에서 로그인하는 이벤트에 반응할 수 있다.
누군가 루트 계정을 사용한다면 이메일을 받는 것. 계정에 좋은 보안 기능이 될 수 있다.

- 함수를 트리거할 목적지가 여러 개라면 SNS와 SQS 메시지로 보낼 수도 있다.
EventBridge가 가운데 있고 Amazon EventBridge로 이벤트를 보낼 수 있는 모든 소스가 있다고하자.
여러 이벤트가 있을 수 있을 것이다.
예를 들면 EC2 인스턴스는 시작할 때, 정지될 때, 종료할 때 등에, CodeBuild는 빌드에 실패할 때가 있을 것이다.
S3는 객체가 업로드될 때와 같은 이벤트가 있을 거고 Trusted Advisor는 계정에 새로운 보안이 있을 때
그리고 EventBridge와 CloudTrail을 결합하는 등이 있을 수 있다. AWS 계정에 발생하는 모든 API 호출을 가로챌 수도 있다.
또한 매 4시간 마다, 혹은 매주 월요일 8시, 아니면 매달 첫 번째 월요일, 이런 식으로 스케줄링도 가능하다.
이런 이벤트는 Amazon EventBridge로 전송되고 필터를 설정할 수 있다. (예를 들면 이벤트가 Amazon S3의 특정 버킷에서 일어났을 때만 본다고 할 수도 있겠다.)
이후 EventBridge는 이벤트 세부사항을 작성한 JSON 문서를 생성한다. 이 JSON 문서는 여러 목적지로 도달하게 되고 여러 작업이 가능해진다.
예를 들어 Lambda 함수를 스케줄링하고 트리거하거나 AWS 배치를 예약하거나, ECS 작업을 할 수 있다.
또는 SQS, SNS 메시지를 보내거나 Kinesis Data Stream으로 보낼 수도 있다.
Step 함수를 시작할 수도 있을 것이고, Code 파이프라인으로 CSD 파이프라인을 시작하거나
CodeBuild로 빌드할 수도 있다. 특정 EC2 작업을 할 수도 있다.
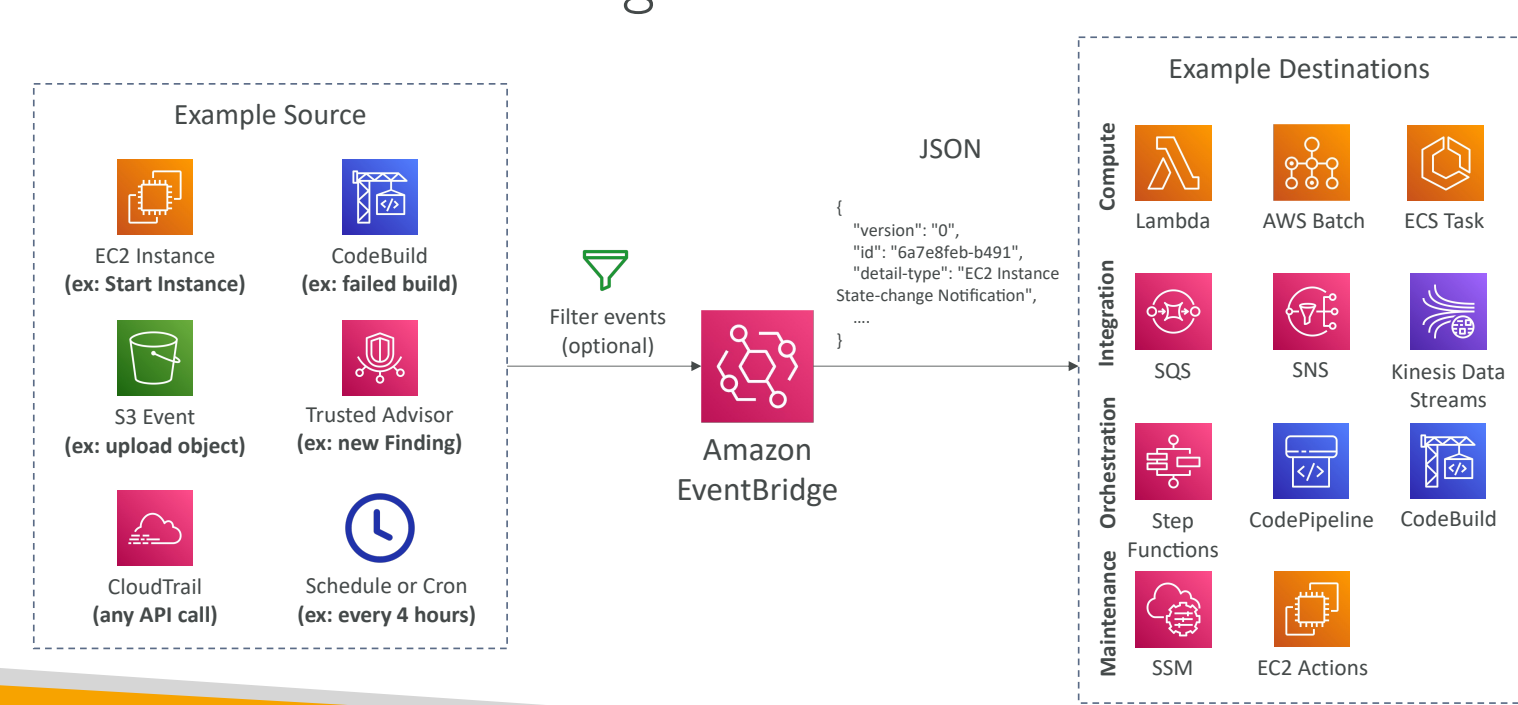
이 모든 걸 알 필요는 없다.
이러한 것들 때문에 EventBrigde는 기본 이벤트 버스라고도 불린다.
그외에도 기능은 많다.
- 파트너 이벤트 버스라는 것인데 AWS가 다른 파트너 서비스와 결합하는 형태이다.
- 이를 통해 다른 서비스에서 이벤트를 파트너 이벤트 버스로 보낼 수 있다.
- 마지막으로 사용자 이벤트 버스가 있다. 즉, 사용자인 내가 직접 이벤트 버스를 만드는 것이다.
- 내 애플리케이션의 이벤트를 사용자 이벤트 버스로 보내서 EventBrigde 규칙에 따라 다른 목적지로 이벤트를 전송할 수 있다.
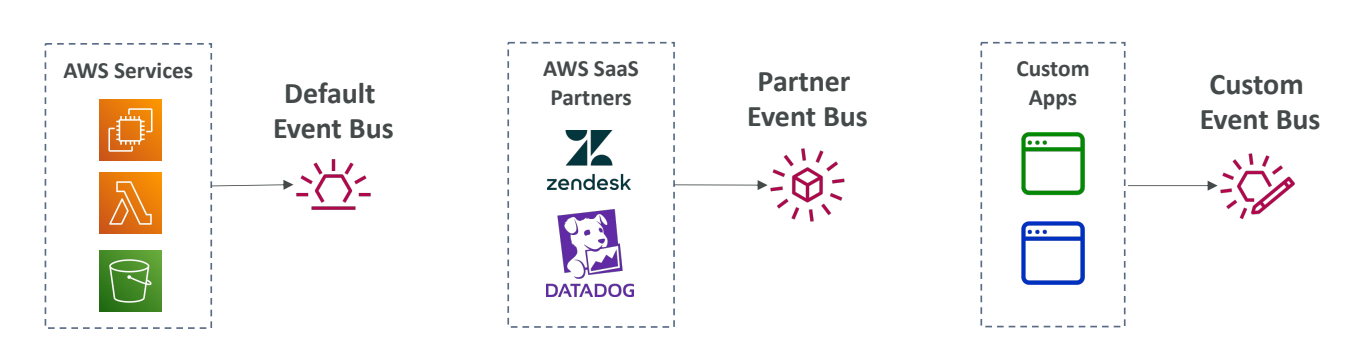
- 리소스 기반 정책을 사용하여 계정간 이벤트 버스에 접근도 가능하다
- 필터를 이용해서 모든 이벤트를 보관도 가능하다
- 영구보관인지 보관 기간을 설정할지 선택할 수 있다.
- 보관된 이벤트를 재현할 수 도 있다. (함수에 버그가 있다고하면 고친다음 이벤트를 재현해서 테스트하는 형태로 이용 가능), 트러블 슈팅에 유용하다.
EventBridge Schema Registry
- EventBridge는 여러 다른 장소, 서비스에서 이벤트를 받기 때문에 이벤트가 어떻게 보이고 구성되는지 이해해야한다.
- EventBridge는 버스의 이벤트를 분석하고 스키마를 추론할 것이다.
- 여기서 Schema Registry를 사용하면 이벤트 버스에서 데이터가 어떻게 구성되는지 미리 알 수 있는 응용 프로그램용 코드를 생성할 수 있다.
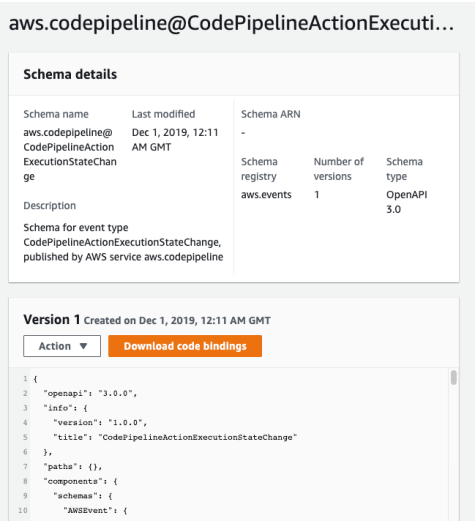
한 파이프라인의 스키마를 코드로 작성한 사진 주황 버튼으로 다운이 가능.
- 여기서 Schema Registry를 사용하면 이벤트 버스에서 데이터가 어떻게 구성되는지 미리 알 수 있는 응용 프로그램용 코드를 생성할 수 있다.
- 스키마를 버전화할 수 있다.
EventBridge - Resource Based Policy
EventBridge는 리소스 기반의 정책이 있다. 즉, 특정 이벤트 버스에 대한 권한을 관리할 수 있다는 뜻이다.
예를 들자면 다른 리전이나 계정의 이벤트를 특정 이벤트 버스가 허용하거나 거부하게 할 수 있다.
사용 사례 : AWS Oragnization 내에 중앙 이벤트 버스가 있고, 계정 세트가 있다.
그리고 이 모든 이벤트는 집계된다고 하자.
특정 계정에 중앙 이벤트 버스가 있고 특정 리소스 기반 정책을 추가하면 다른 계정에서 이벤트를 보낼 수 있게 되는 것이다. 따라서 이 다른 계정은 중앙 이벤트 버스에 직접 이벤트를 보낼 수 있게 된다.
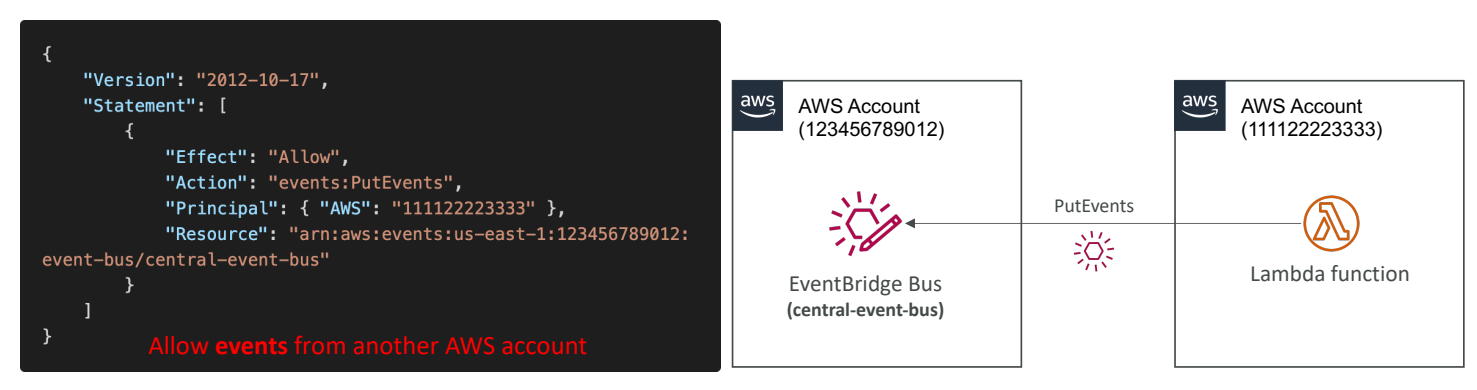
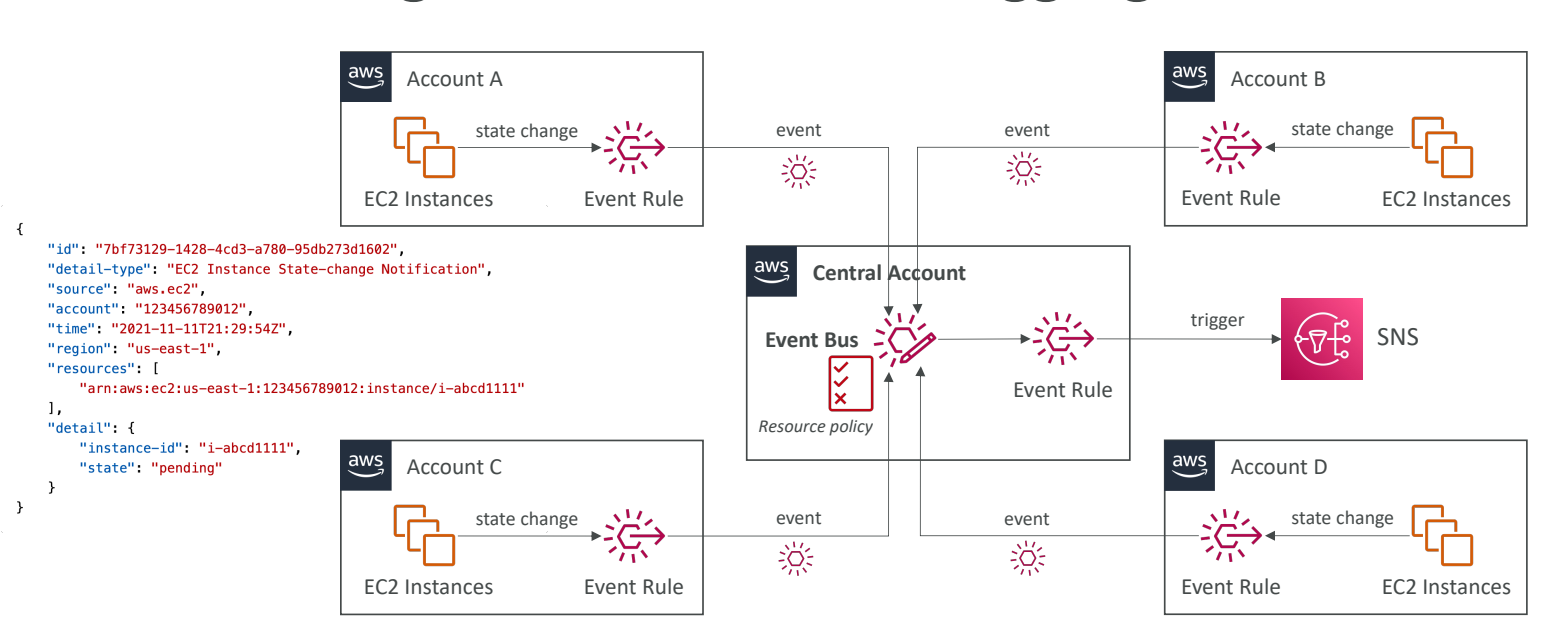
EventBridge - Multi-account Aggregation
여러 계정의 이벤트를 통합하는 법이다. 중앙 계정의 이벤트 버스에서 몇몇의 이벤트를 중앙 집중식으로 관리할 거라고 하자. 또한 모든 계정에서 EC2 인스턴스를 시작하고 그 이벤트를 중앙 계정에서 캐치할 것이라고 하면 어떻게 해야할까?
한 계정에 이벤트 패턴을 정의하고 규칙을 생성하면 된다. 또한 중앙 이벤트 버스에 리소스 정책을 생성해서 다른 계정의 이벤트를 수용하도록 하면 된다.
2024.03.11 - [분류 전체보기] - [AWS 스터디모임] AWS Monitoring, Troubleshooting & Audits(2)
'AWS' 카테고리의 다른 글
| [AWS 스터디모임] AWS Monitoring, Troubleshooting & Audits(2) (0) | 2024.03.11 |
|---|---|
| [AWS 스터디 모임] ElasticCache 생성해보기 (0) | 2024.03.04 |
| [AWS 스터디모임] ElasticCache (0) | 2024.03.04 |
| [AWS 스터디모임] EC2 Instance Storage (0) | 2024.02.26 |
| [AWS 스터디모임] RDS 실습해보기 (0) | 2024.02.19 |



